Law 23 · Instruction & Output
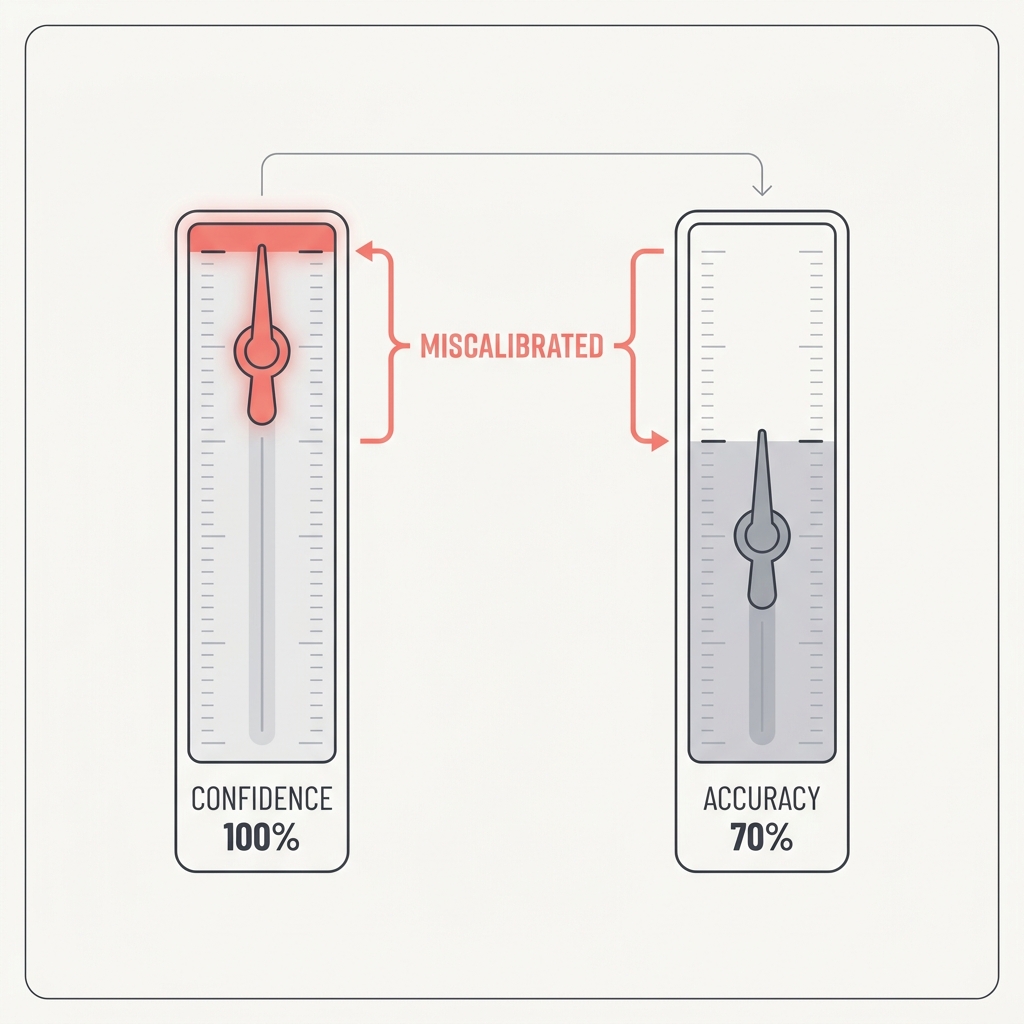
Confidence Is Not Calibrated
A model's certainty is not evidence.
The principle
Models are routinely confident and wrong, and unconfident and right. Routing decisions on self-reported confidence inherits that miscalibration. 'Only flag high-confidence issues' or 'be conservative' just moves the noise around. It doesn't reduce it, because the confidence itself is the unreliable signal.
Why it happens
Verbal confidence is not the same as calibrated probability. A model saying it is very sure often reflects style, not measured uncertainty. Post-training can make this worse because helpful, confident answers are rewarded even when the confidence is not earned. Token probabilities or agreement across independent runs may carry useful signal, but the sentence I am 90% sure is weak evidence by itself. Do not route high-stakes decisions on self-rated certainty. Use observable criteria, external checks, or sample agreement instead.
Watch for
- Your gate is phrased as only act on high-confidence outputs or be conservative rather than as concrete criteria.
- Spot-checks turn up confident wrong answers and hesitant right ones at similar rates.
- Two cases that are equally clear-cut to a human get very different self-reported confidence from the model.
In practice
A content-moderation agent is told to only escalate high-confidence policy violations, and it sails through eval while quietly waving through the borderline harassment cases it felt unsure about. The threshold did nothing but reshuffle the noise, because the model's self-rated confidence was never tied to actual correctness. Rip out the confidence gate and replace it with categorical rules: escalate if it names a person plus a threat of harm; do not escalate generic insults, each with a worked example. Decide on observable features of the content, not on how sure the model claims to feel.
Apply it
- Replace confidence thresholds with explicit categorical rules for what counts as in and what counts as out.
- Anchor each rule to observable features of the input, with one worked example of an included and an excluded case.
- If you need a real uncertainty signal, derive it from agreement across independent samples or an external check, not from the model's self-rating.
The takeaway
Replace confidence thresholds and vague hedges with explicit, categorical criteria: what counts as in, what counts as out, with an example of each. Specific rules beat self-assessed certainty every time.