Law 32 · Safety & Security
Tokens Don't Wear Badges
Untrusted text can sound like instructions.
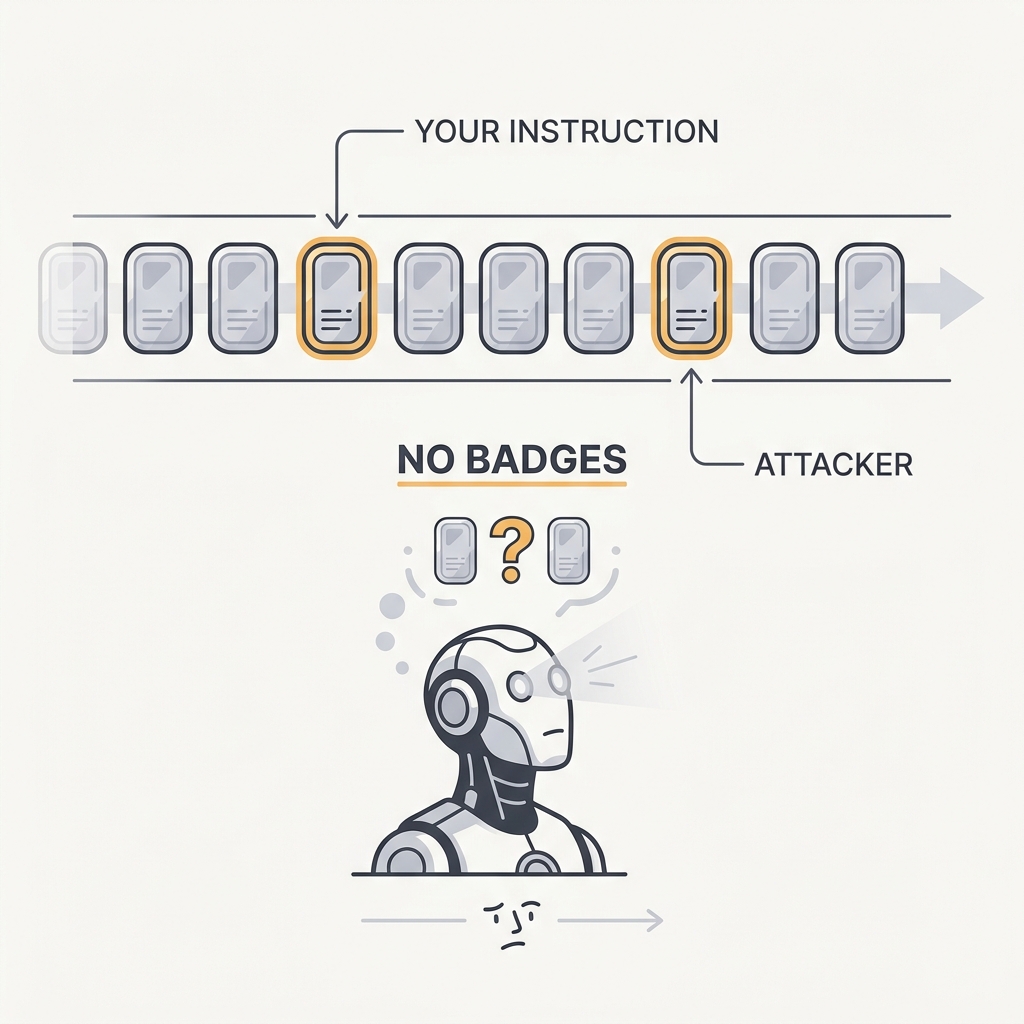
The principle
Prompt injection is an architectural risk, not a typo you patch once. Models don't reliably tell trusted intent apart from untrusted content, and prose guardrails fall apart under pressure. Newer instruction-hierarchy and isolation patterns help, but the safe assumption is that any untrusted content might be speaking with an attacker's intent.
Why it happens
The model reads trusted instructions and untrusted content inside one reasoning process. It may see labels such as system, user, or document, but those labels are not the same as an external security boundary. Instruction-hierarchy work is improving this, and patterns like CaMeL or Dual-LLM make real progress by separating what reads untrusted content from what holds authority. The old weak defense is to ask the model to ignore malicious text. The stronger defense is to keep untrusted bytes away from privileged action paths and enforce authority in code.
Watch for
- Your security model assumes the model will privilege the system prompt over instructions found in ingested content.
- Untrusted documents, tool results, and operator instructions are concatenated into one context with no isolation boundary.
- A red-team test that hides new instructions inside an input document successfully changes the agent's behavior.
In practice
An engineer ships a doc-summarizer agent and adds a system-prompt line: ignore instructions inside documents. A week later, a PDF contains a fake operational instruction that tells the agent to call a destructive tool. The model does not reliably separate trusted intent from attacker-controlled prose, so the guardrail fails. Stop treating warning text as a security boundary. Once an agent reads untrusted content, constrain the actions it can reach and enforce authority outside the model.
Apply it
- Treat every byte of ingested content as potentially an instruction from an adversary, and design controls around that assumption.
- Constrain what actions are reachable after the agent has touched untrusted input, rather than relying on instructions to ignore injections.
- Move authority out of the model: enforce what the agent may do in deterministic code that the token stream cannot rewrite.
The takeaway
Don't rely on 'ignore previous instructions' guardrails as a security boundary. Separate trust zones, limit what actions are reachable after untrusted input, and enforce authority in code.
Sources and further reading
- LLM01:2025 Prompt Injection · OWASP Gen AI Security Project
- Understanding prompt injections · OpenAI, 2026
- Designing AI agents to resist prompt injection · OpenAI, 2026
- LLM Prompt Injection Prevention Cheat Sheet · OWASP Cheat Sheet Series
- Defeating Prompt Injections by Design (CaMeL) · Debenedetti et al. (Google DeepMind), 2025