Law 41 · Architecture & Operations
Trip the Breaker
Stop calling the thing that's already failing.
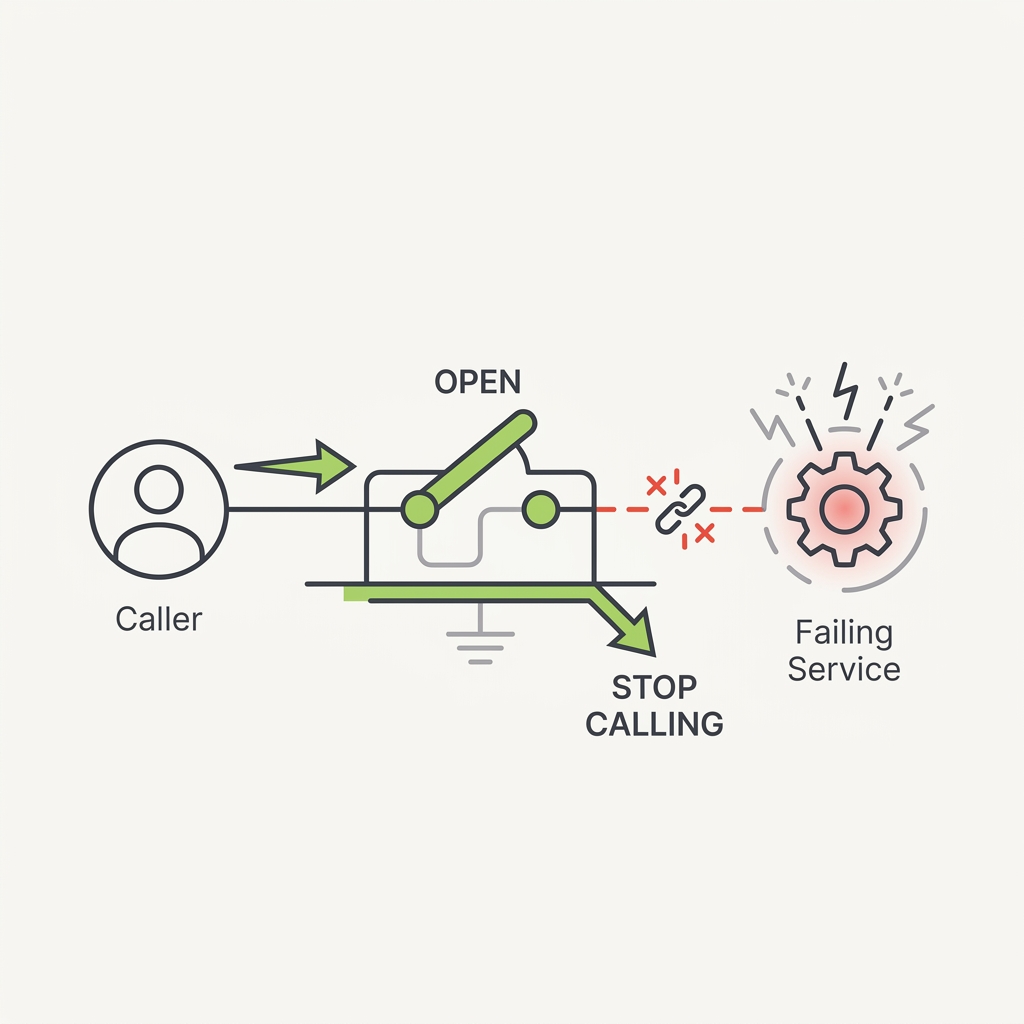
The principle
A downstream model or tool that's timing out doesn't get healthier by being called more. It gets worse, while your agents pile up holding open connections and burning their latency budget. A circuit breaker wraps the call so that once failures cross a threshold it trips, and further calls fail fast instead of hanging, which gives the dependency room to recover.
Why it happens
A failing dependency does not heal because agents keep calling it. More calls add load, tie up connections, and push the failure outward. A circuit breaker counts failures and opens after a threshold, so later calls fail fast instead of hanging. After a cooldown, a small probe checks whether the dependency has recovered. The point is not elegance; it is containment. A predictable fast failure can be handled. A thousand slow hangs become an outage. Pair the breaker with retry shedding so recovery is not drowned by traffic.
Watch for
- When a downstream model or tool slows down, your agents respond by retrying harder and connections pile up.
- A single failing dependency drags whole-run latency toward your timeout ceiling instead of failing fast.
- There is no fast-fail path: calls to a known-sick dependency hang until they time out individually.
In practice
A downstream embedding service starts timing out, and your agents respond by hammering it harder on every retry, piling up open connections and dragging the whole run's latency into the floor while the sick dependency gets sicker. Calling a failing service more never heals it. Wrap that dependency in a circuit breaker: once failures cross a threshold it trips and calls fail fast instead of hanging, then it periodically probes for recovery. Your agents degrade gracefully on a known error path instead of stalling indefinitely behind a dependency that is not coming back.
Apply it
- Wrap every external model and tool dependency in a breaker that opens after a failure threshold and fails fast.
- After a cooldown, let a single probe test recovery before resuming full traffic.
- Shed retries and traffic upstream when load exceeds capacity so retries do not amplify the cascade.
The takeaway
Wrap every external model and tool dependency in a circuit breaker that fails fast after a failure threshold, then probes for recovery. Don't let one sick dependency drag the whole run down.